1 indicates co-first authors
All
2026
AGIS: Fast Approximate Graph Pattern Mining with Structure-Informed Sampling
Proceedings of International Conference on Very Large Data Bases (VLDB)
·
Aug 2026
·
To appear
2025
DMO-DB: Mitigating the Data Movement Bottlenecks of GPU-Accelerated Relational OLAP
International Conference on Parallel Architectures and Compilation Techniques (PACT)
·
Nov 2025
·
To appear

FALA: Locality-Aware PIM-Host Cooperation for Graph Processing with Fine-Grained Column Access
IEEE/ACM International Symposium on Microarchitecture (MICRO)
·
Oct 2025
·
To appear
CrossBit: Bitwise Computing in NAND Flash Memory with Inter-Bitline Data Communication
IEEE/ACM International Symposium on Microarchitecture (MICRO)
·
Oct 2025
·
To appear

PathWeaver: A High-Throughput Multi-GPU System for Graph-Based Approximate Nearest Neighbor Search
USENIX Annual Technical Conference (USENIX ATC)
·
Jul 2025
·
To appear

DANCE++: Differentiable Accelerator/Network Co-Exploration with Hard Constraints and Data-Free Training for Real-World Scenarios
IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD)
·
Jun 2025
·
To appear

G³SA: A GPU-Accelerated Gold Standard Genomics Library for End-to-End Sequence Alignment
International Conference on Supercomputing (ICS)
·
Jun 2025
·
To appear
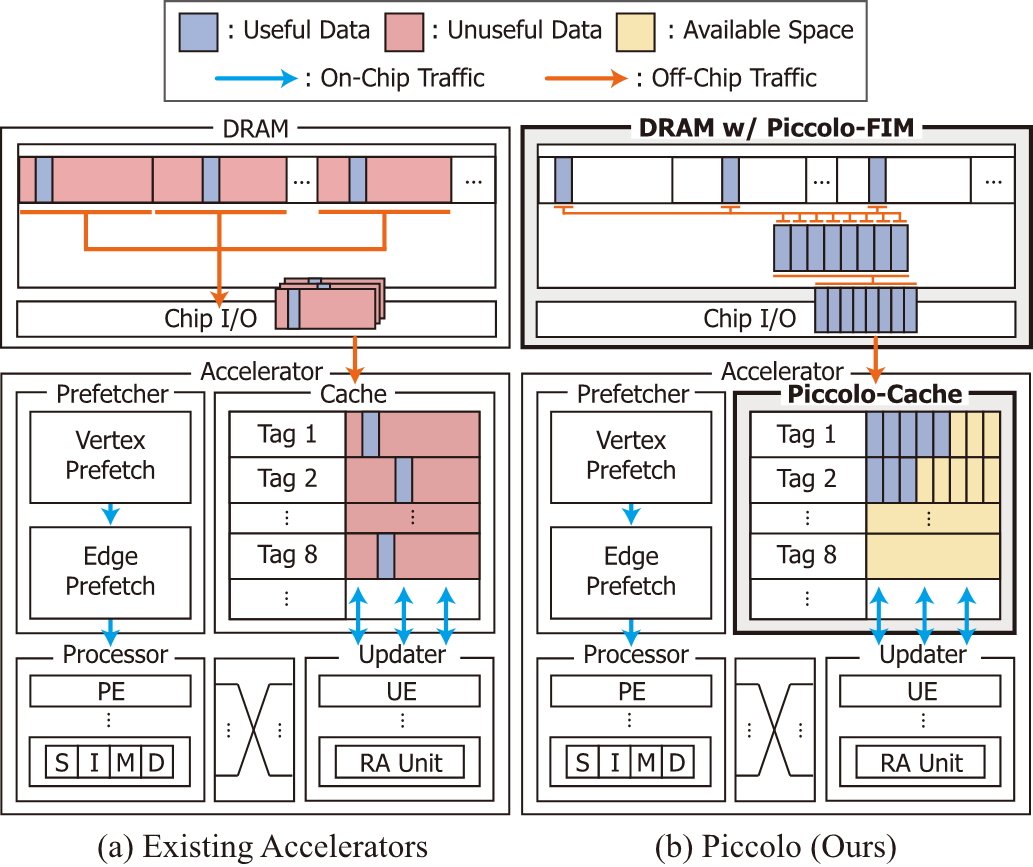
Piccolo: Large-Scale Graph Processing with Fine-Grained In-Memory Scatter-Gather
International Symposium on High-Performance Computer Architecture (HPCA)
·
Mar 2025
·
10.1109/HPCA61900.2025.00055
MimiQ: Low-Bit Data-Free Quantization of Vision Transformers with Encouraging Inter-Head Attention Similarity
AAAI Conference on Artificial Intelligence (AAAI)
·
Feb 2025
·
10.1609/aaai.v39i15.33761
2024
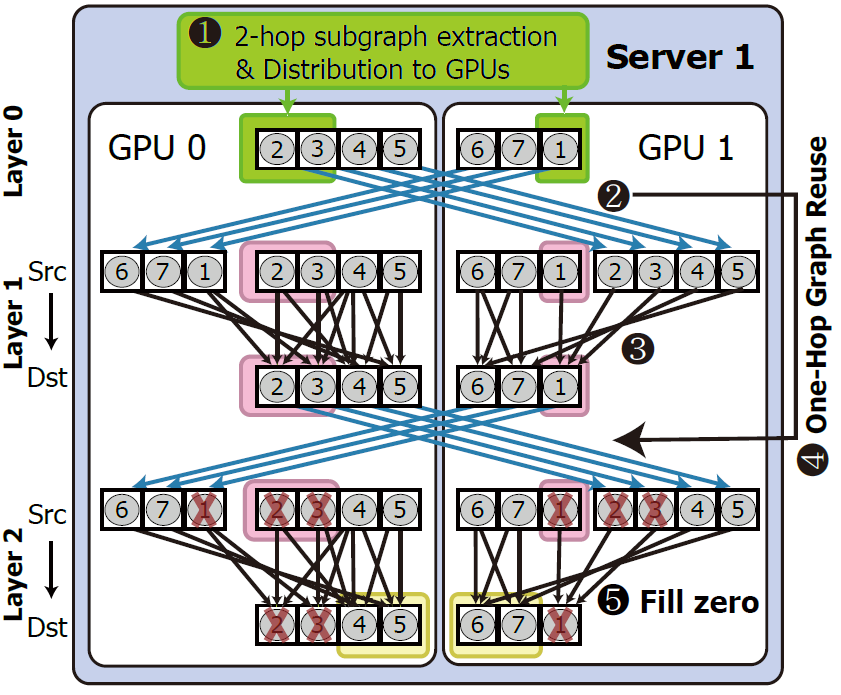
GraNNDis: Fast Distributed Graph Neural Network Training Framework for Multi-Server Clusters
The International Conference on Parallel Architectures and Compilation Techniques (PACT)
·
Oct 2024
·
10.1145/3656019.3676892
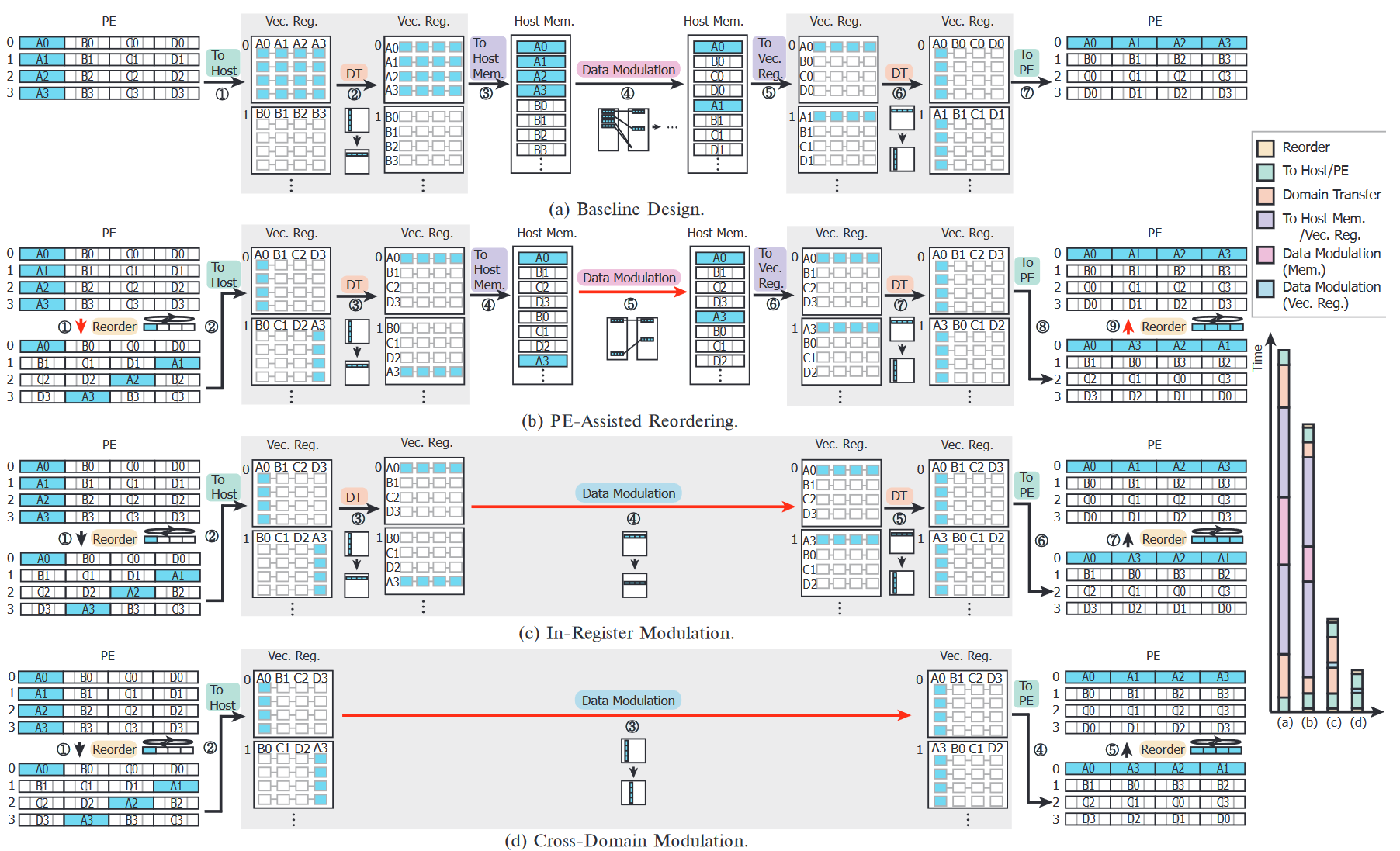
PID-Comm: A Fast and Flexible Collective Communication Framework for Commodity Processing-in-DIMMs
International Symposium on Computer Architecture (ISCA)
·
Jul 2024
·
10.1109/ISCA59077.2024.00027
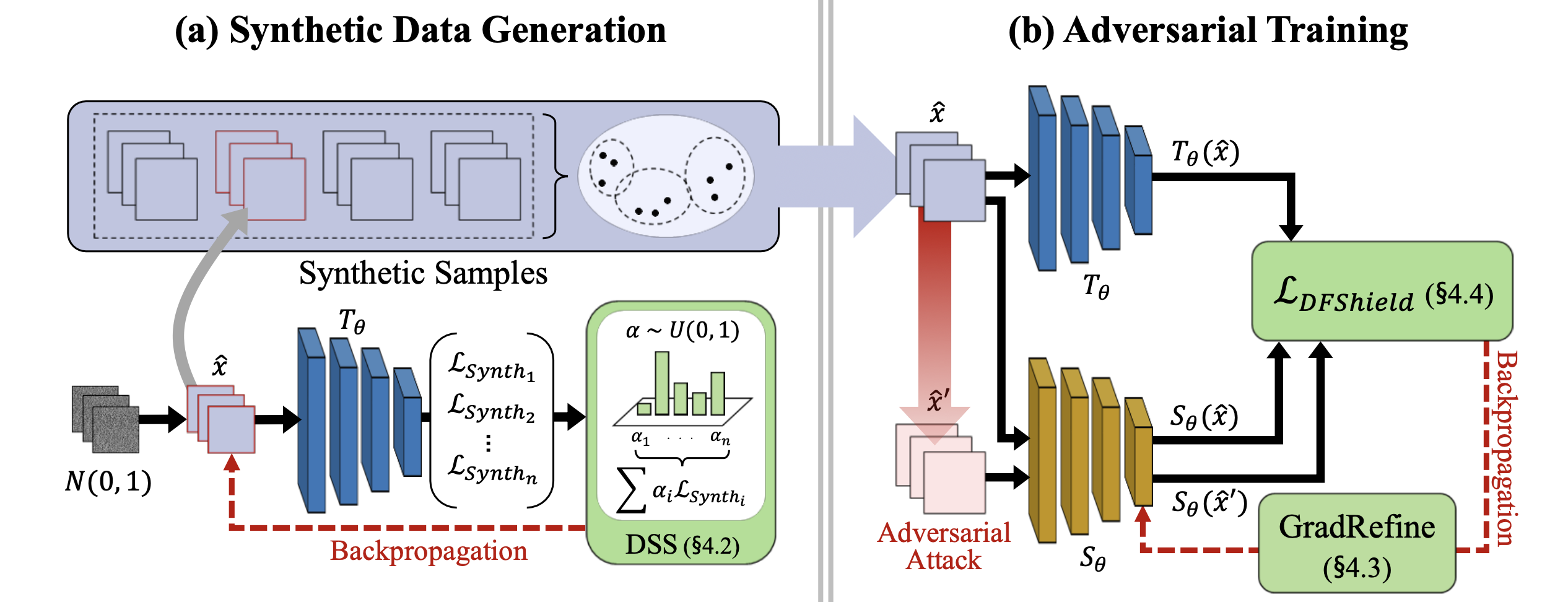
DataFreeShield: Defending Adversarial Attacks without Training Data
International Conference on Machine Learning (ICML)
·
May 2024
·
10.48550/arXiv.2406.15635
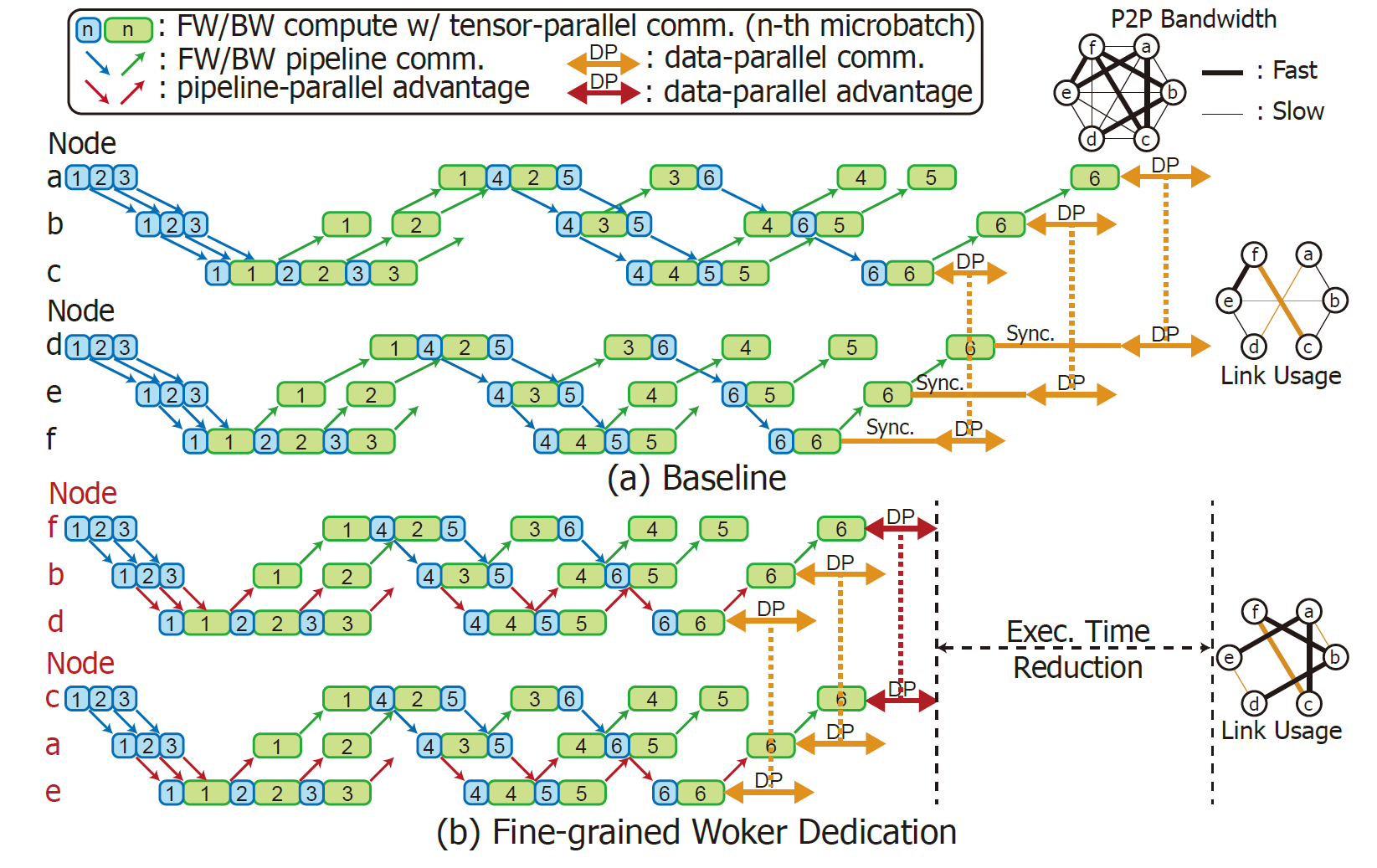
Pipette: Automatic Fine-Grained Large Language Model Training Configurator for Real-World Clusters
Design, Automation and Test in Europe Conference (DATE)
·
Mar 2024
·
10.23919/DATE58400.2024.10546826
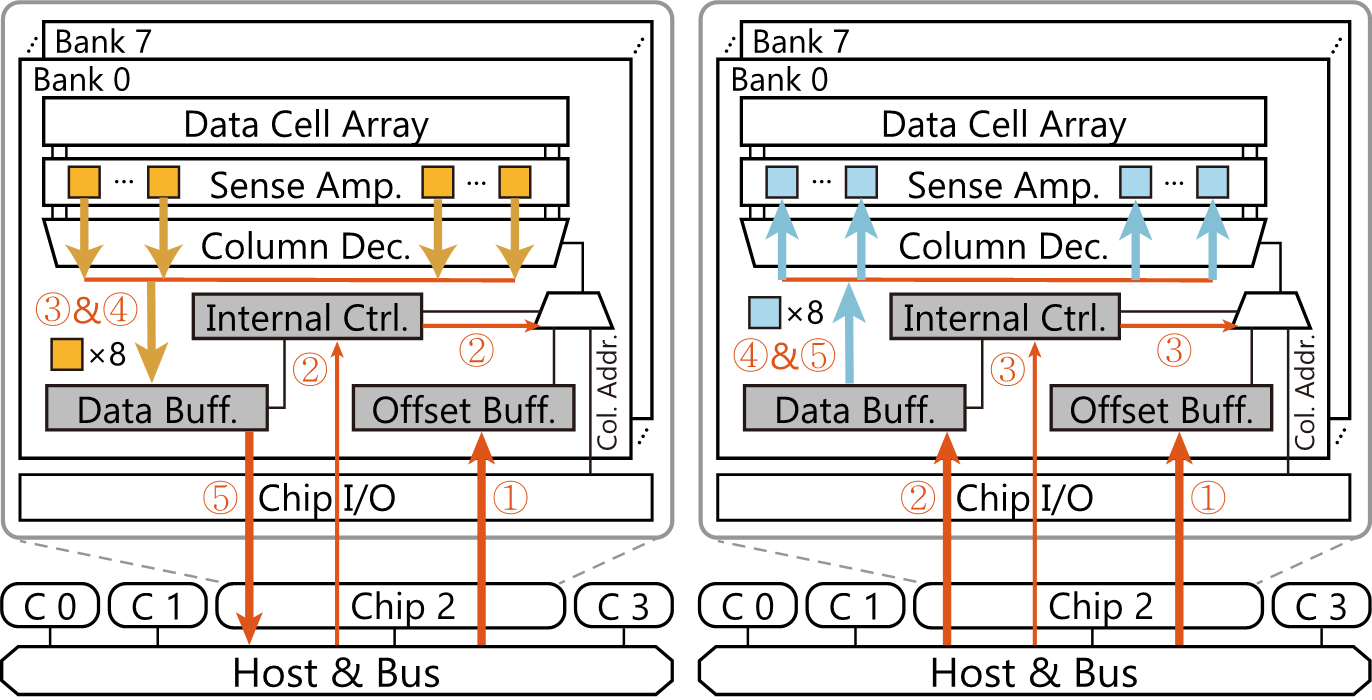
A Case for In-Memory Random Scatter-Gather for Fast Graph Processing
IEEE Computer Architecture Letters (CAL)
·
Mar 2024
·
10.1109/LCA.2024.3376680
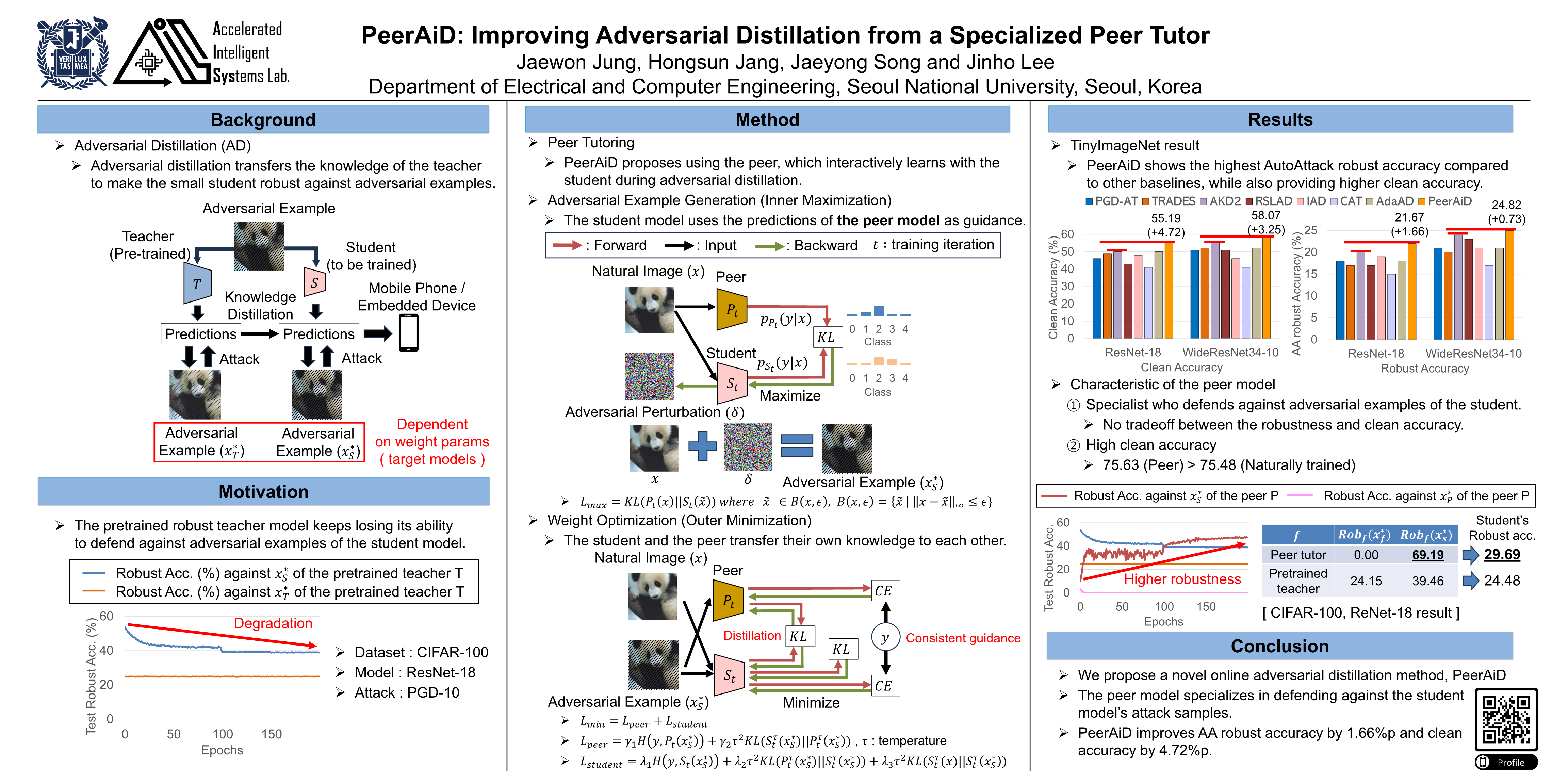
PeerAiD: Improving Adversarial Distillation from a Specialized Peer Tutor
Computer Vision and Pattern Recognition Conference (CVPR)
·
Mar 2024
·
10.48550/arXiv.2403.06668
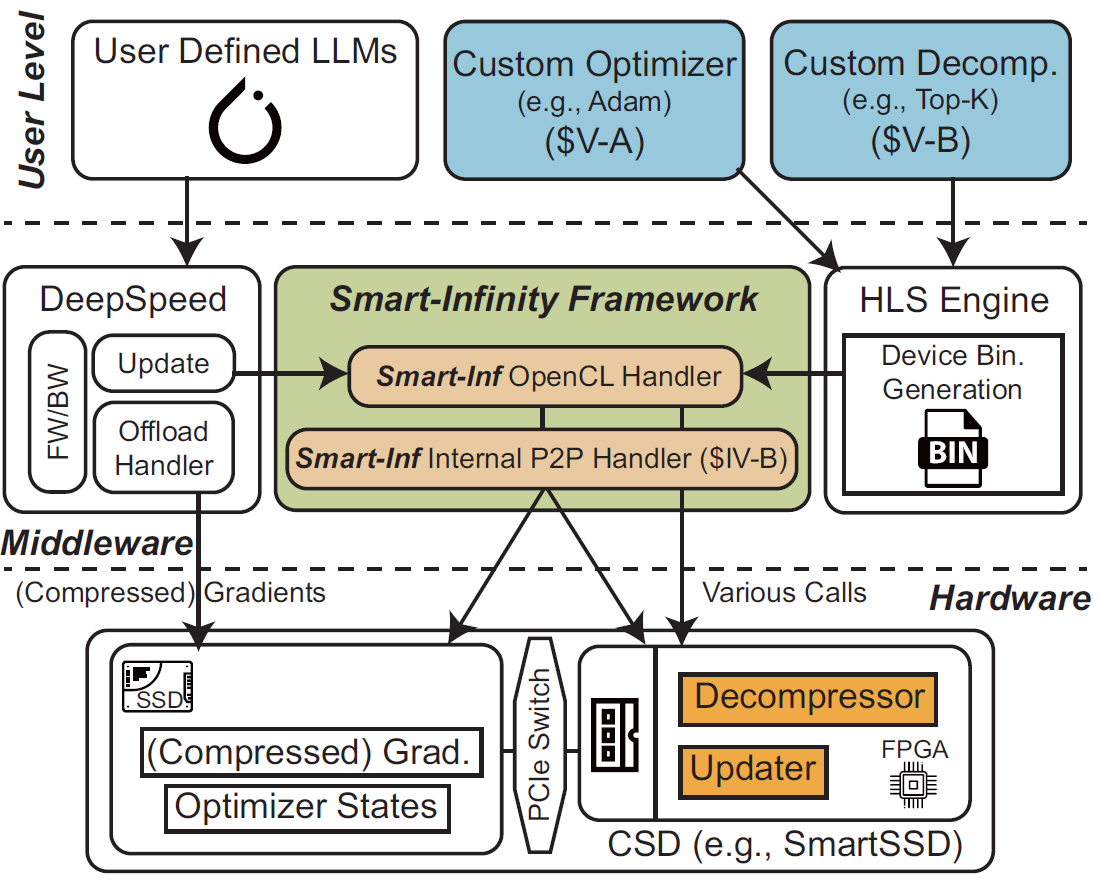
Smart-Infinity: Fast Large Language Model Training using Near-Storage Processing on a Real System
Best Paper Award-Honorable Mention, International Symposium on High-Performance Computer Architecture (HPCA)
·
Mar 2024
·
10.1109/HPCA57654.2024.00034
AGAThA: Fast and Efficient GPU Acceleration of Guided Sequence Alignment for Long Read Mapping
ACM Annual Symposium on Principles and Practice of Parallel Programming (PPoPP)
·
Feb 2024
·
10.1145/3627535.3638474
2023
Enabling Fine-Grained Spatial Multitasking on Systolic-Array NPUs Using Dataflow Mirroring
IEEE Transactions on Computers
·
Dec 2023
·
10.1109/TC.2023.3299030
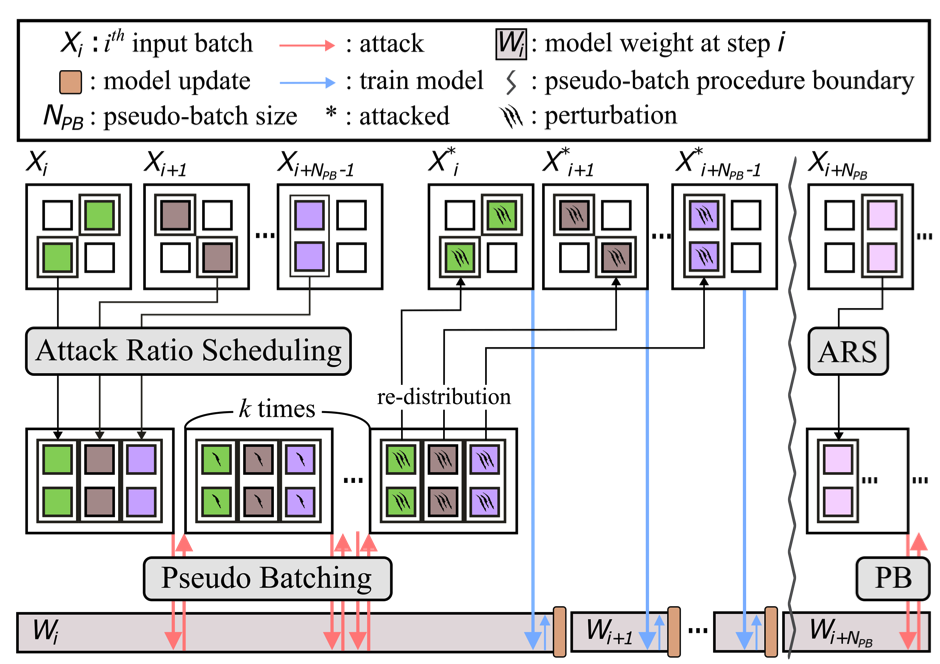
Fast Adversarial Training with Dynamic Batch-level Attack Control
Design Automation Conference (DAC)
·
Jul 2023
·
10.1109/DAC56929.2023.10247930
Design and Analysis of a Processing-in-DIMM Join Algorithm: A Case Study with UPMEM DIMMs
Proceedings of the ACM on Management of Data
·
Jun 2023
·
10.1145/3589258
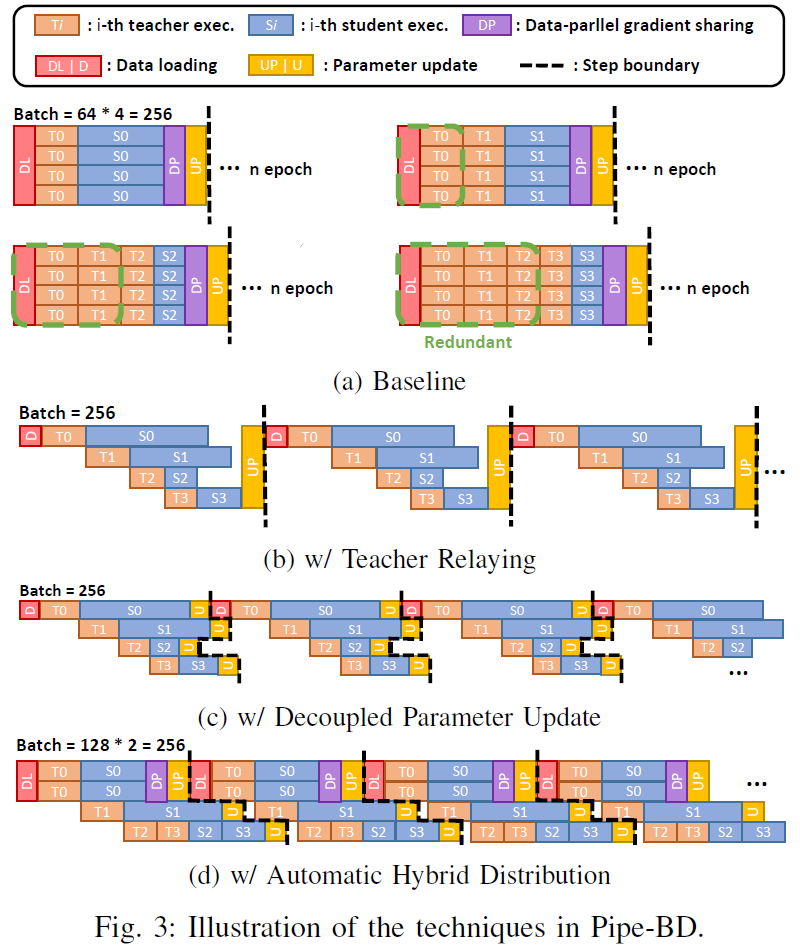
Pipe-BD: Pipelined Parallel Blockwise Distillation
2023 Design, Automation & Test in Europe Conference & Exhibition (DATE)
·
Apr 2023
·
10.23919/DATE56975.2023.10137044
SGCN: Exploiting Compressed-Sparse Features in Deep Graph Convolutional Network Accelerators
2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA)
·
Feb 2023
·
10.1109/HPCA56546.2023.10071102
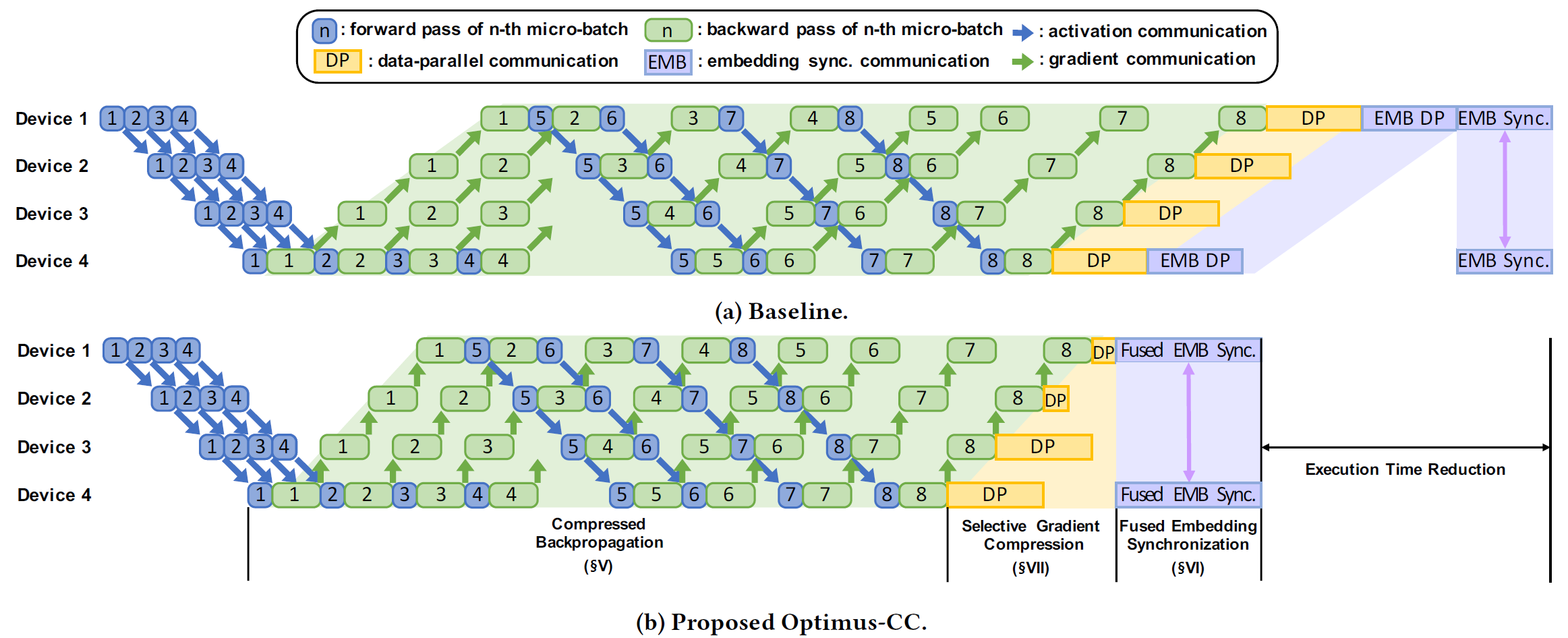
Optimus-CC: Efficient Large NLP Model Training with 3D Parallelism Aware Communication Compression
Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2
·
Jan 2023
·
10.1145/3575693.3575712
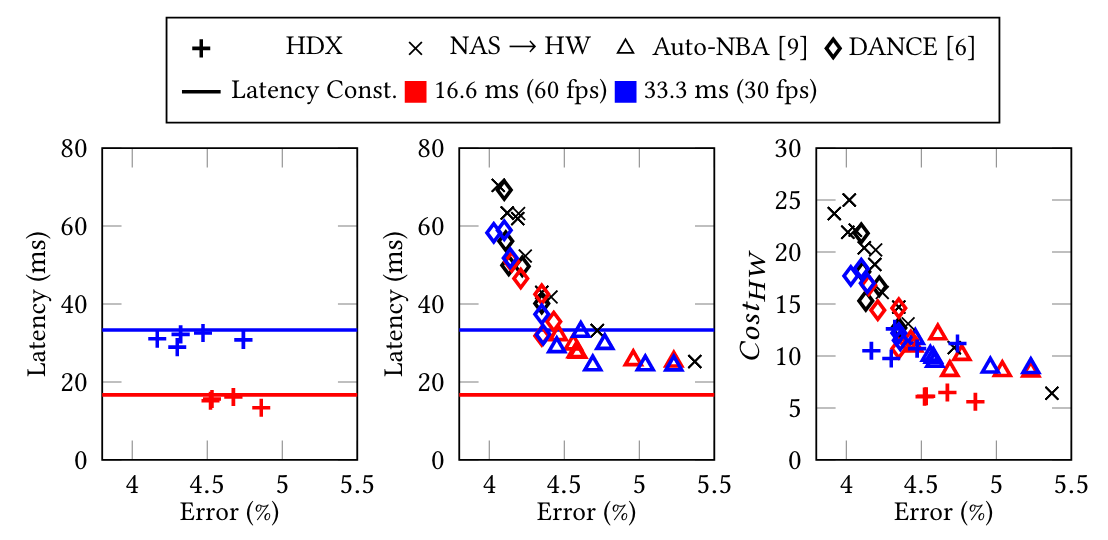
Enabling Hard Constraints in Differentiable Neural Network and Accelerator Co-Exploration
Design Automation Conference (DAC)
·
Jan 2023
·
arxiv:2301.09312
2022
Improving Gradient Paths for Binary Convolutional Neural Networks
BMVC
·
Nov 2022
·
https://bmvc2022.mpi-inf.mpg.de/281/
GuardiaNN: Fast and Secure On-Device Inference in TrustZone Using Embedded SRAM and Cryptographic Hardware
Proceedings of the 23rd ACM/IFIP International Middleware Conference
·
Oct 2022
·
10.1145/3528535.3531513
Decoupling Schedule, Topology Layout, and Algorithm to Easily Enlarge the Tuning Space of GPU Graph Processing
Proceedings of the International Conference on Parallel Architectures and Compilation Techniques
·
Oct 2022
·
10.1145/3559009.3569686
Slice-and-Forge: Making Better Use of Caches for Graph Convolutional Network Accelerators
PACT (Best Paper Award)
·
Oct 2022
·
10.1145/3559009.3569693
ComPreEND: Computation Pruning through Predictive Early Negative Detection for ReLU in a Deep Neural Network Accelerator
IEEE Transactions on Computers
·
Jul 2022
·
10.1109/TC.2021.3092205
GCoM: a detailed GPU core model for accurate analytical modeling of modern GPUs
Proceedings of the 49th Annual International Symposium on Computer Architecture
·
Jun 2022
·
10.1145/3470496.3527384
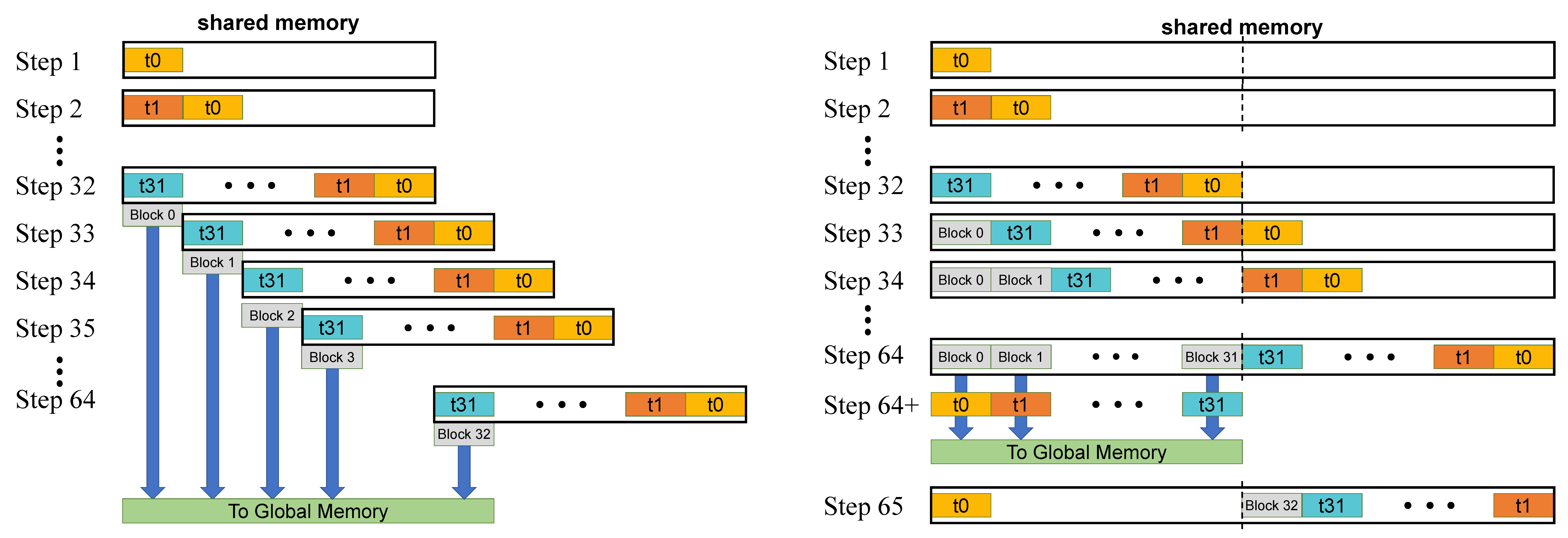
SALoBa: Maximizing Data Locality and Workload Balance for Fast Sequence Alignment on GPUs
2022 IEEE International Parallel and Distributed Processing Symposium (IPDPS)
·
May 2022
·
10.1109/IPDPS53621.2022.00076
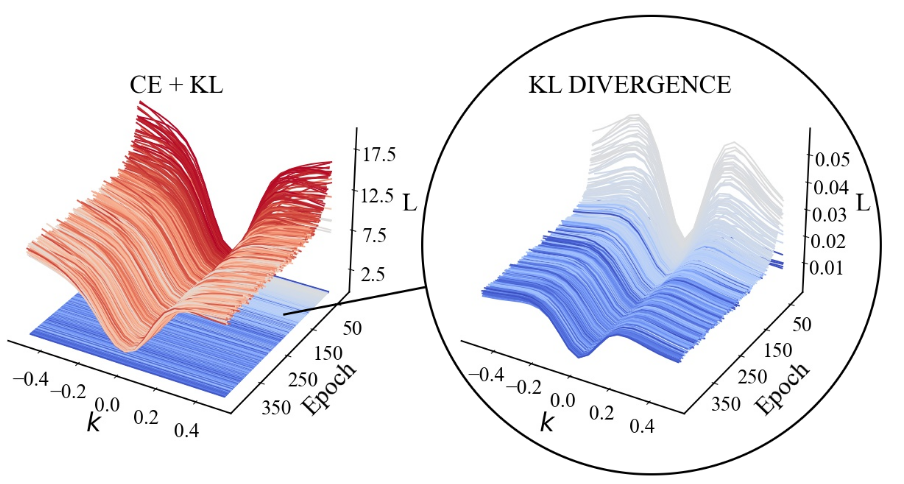
It's All In the Teacher: Zero-Shot Quantization Brought Closer to the Teacher
Computer Vision and Pattern Recognition Conference (CVPR)
·
Apr 2022
·
arxiv:2203.17008
2021
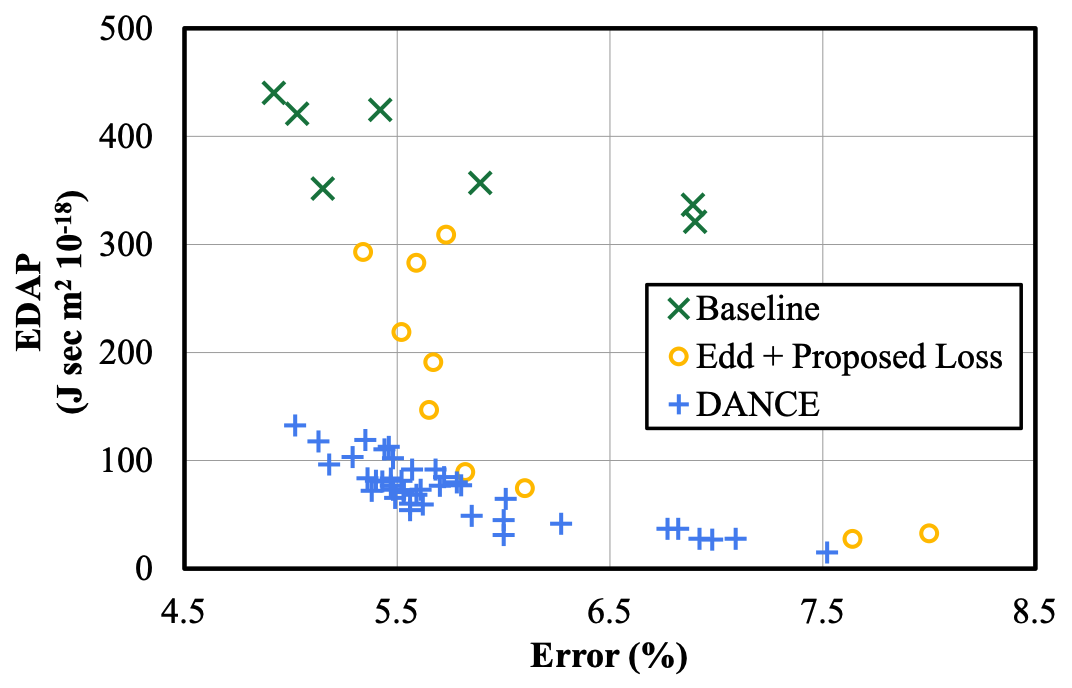
DANCE: Differentiable Accelerator/Network Co-Exploration
Design Automation Conference (DAC)
·
Dec 2021
·
10.1109/DAC18074.2021.9586121
Dataflow Mirroring: Architectural Support for Highly Efficient Fine-Grained Spatial Multitasking on Systolic-Array NPUs
2021 58th ACM/IEEE Design Automation Conference (DAC)
·
Dec 2021
·
10.1109/DAC18074.2021.9586312
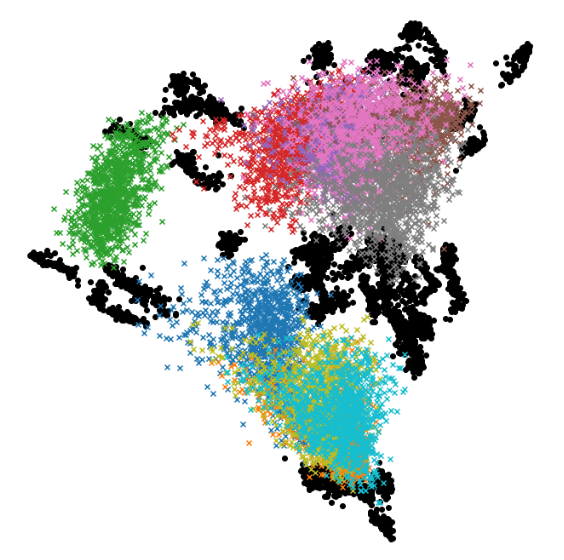
Qimera: Data-free Quantization with Synthetic Boundary Supporting Samples
Neural Information Processing Systems (NeurIPS)
·
Nov 2021
·
arxiv:2111.02625
AutoReCon: Neural Architecture Search-based Reconstruction for Data-free Compression
IJCAI
·
Aug 2021
·
https://www.ijcai.org/proceedings/2021/478
Making a Better Use of Caches for GCN Accelerators with Feature Slicing and Automatic Tile Morphing
IEEE Computer Architecture Letters
·
Jul 2021
·
10.1109/LCA.2021.3090954
GradPIM: A Practical Processing-in-DRAM Architecture for Gradient Descent
2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA)
·
Feb 2021
·
10.1109/HPCA51647.2021.00030
2020

Deep Composer Classification Using Symbolic Representation
LBD@ISMIR
·
Oct 2020
·
arxiv:2010.00823
FlexReduce: Flexible All-reduce for Distributed Deep Learning on Asymmetric Network Topology
2020 57th ACM/IEEE Design Automation Conference (DAC)
·
Jul 2020
·
10.1109/DAC18072.2020.9218538
MUTE: Inter-class Ambiguity Driven Multi-hot Target Encoding for Deep Neural Network Design
2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
·
Jun 2020
·
10.1109/CVPRW50498.2020.00385
An Efficient High-Throughput LZ77-Based Decompressor in Reconfigurable Logic
Journal of Signal Processing Systems
·
May 2020
·
10.1007/s11265-020-01547-w
SimEx: Express Prediction of Inter-dataset Similarity by a Fleet of Autoencoders
arXiv preprint
·
Jan 2020
·
https://arxiv.org/abs/2001.04893
2019
In-memory database acceleration on FPGAs: a survey
The VLDB Journal
·
Oct 2019
·
10.1007/s00778-019-00581-w
Video-Text Compliance: Activity Verification Based on Natural Language Instructions
2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW)
·
Oct 2019
·
10.1109/ICCVW.2019.00188
An Efficient Graph Compressor Based on Adaptive Prefix Encoding
Proceedings of the 31st International Conference on Scientific and Statistical Database Management
·
Jul 2019
·
10.1145/3335783.3335786
Refine and Recycle: A Method to Increase Decompression Parallelism
2019 IEEE 30th International Conference on Application-specific Systems, Architectures and Processors (ASAP)
·
Jul 2019
·
10.1109/ASAP.2019.00017
A Diagnosable Network-on-Chip for FPGA Verification of Intellectual Properties
IEEE Design & Test
·
Apr 2019
·
10.1109/MDAT.2018.2890238
Accelerating Conversational Agents Built With Off-the-Shelf Modularized Services
IEEE Pervasive Computing
·
Apr 2019
·
10.1109/MPRV.2019.2907004
2018
Deep neural networks with weighted spikes
Neurocomputing
·
Oct 2018
·
10.1016/j.neucom.2018.05.087
My Being to Your Place, Your Being to My Place
Proceedings of the 16th Annual International Conference on Mobile Systems, Applications, and Services
·
Jun 2018
·
10.1145/3210240.3210348
System G Distributed Graph Database
arXiv
·
Feb 2018
·
https://arxiv.org/abs/1802.03057
TEI-NoC: Optimizing Ultralow Power NoCs Exploiting the Temperature Effect Inversion
IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems
·
Feb 2018
·
10.1109/TCAD.2017.2693269
2017
Scalable time-versioning support for property graph databases
2017 IEEE International Conference on Big Data (Big Data)
·
Dec 2017
·
10.1109/BigData.2017.8258092
Analyzing In-Memory Hash Joins: Granularity Matters
ADMS workshop @VLDB
·
Aug 2017
·
To appear
ExtraV: boosting graph processing near storage with a coherent accelerator
Proceedings of the VLDB Endowment
·
Aug 2017
·
10.14778/3137765.3137776
Excavating the Hidden Parallelism Inside DRAM Architectures With Buffered Compares
IEEE Transactions on Very Large Scale Integration (VLSI) Systems
·
Jun 2017
·
10.1109/TVLSI.2017.2655722
SCI-FII: Speculative Conversational Interface Framework for Incremental Inference on Modularized Services
2017 18th IEEE International Conference on Mobile Data Management (MDM)
·
May 2017
·
10.1109/MDM.2017.45
2016
Buffered compares: excavating the hidden parallelism inside DRAM architectures with lightweight logic
2016 Design, Automation and Test in Europe Conference (DATE)
·
Mar 2016
·
10.3850/9783981537079_0512
2015
REDELF: An Energy-Efficient Deadlock-Free Routing for 3D NoCs with Partial Vertical Connections
ACM Journal on Emerging Technologies in Computing Systems (JETC)
·
Sep 2015
·
10.1145/2751560
THOR: Orchestrated thermal management of cores and networks in 3D many-core architectures
The 20th Asia and South Pacific Design Automation Conference
·
Jan 2015
·
10.1109/ASPDAC.2015.7059104
2014
Tree-Mesh Heterogeneous Topology for Low-Latency NoC
Proceedings of the 2014 International Workshop on Network on Chip Architectures
·
Dec 2014
·
10.1145/2685342.2685346
2013
Towards optimal adaptive routing in 3D NoC with limited vertical bandwidth
Proceedings of the Sixth International Workshop on Network on Chip Architectures
·
Dec 2013
·
10.1145/2536522.2536534
Mapping and Scheduling of Tasks and Communications on Many-Core SoC Under Local Memory Constraint
IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems
·
Nov 2013
·
10.1109/TCAD.2013.2266405
Deflection routing in 3D network-on-chip with limited vertical bandwidth
ACM Transactions on Design Automation of Electronic Systems
·
Oct 2013
·
10.1145/2505011
A deadlock-free routing algorithm requiring no virtual channel on 3D-NoCs with partial vertical connections
2013 Seventh IEEE/ACM International Symposium on Networks-on-Chip (NoCS)
·
Apr 2013
·
10.1109/NoCS.2013.6558407
Deflection routing in 3D Network-on-Chip with TSV serialization
2013 18th Asia and South Pacific Design Automation Conference (ASP-DAC)
·
Jan 2013
·
10.1109/ASPDAC.2013.6509554
2012
An adaptive routing algorithm for 3D mesh NoC with limited vertical bandwidth
2012 IEEE/IFIP 20th International Conference on VLSI and System-on-Chip (VLSI-SoC)
·
Oct 2012
·
10.1109/VLSI-SoC.2012.6378999
Memory-aware mapping and scheduling of tasks and communications on many-core SoC
17th Asia and South Pacific Design Automation Conference
·
Jan 2012
·
10.1109/ASPDAC.2012.6164985
2011
3D network-on-chip with wireless links through inductive coupling
2011 International SoC Design Conference
·
Nov 2011
·
10.1109/isocc.2011.6138783
2009
Leakage power reduction of functional units in processors having zero-overhead loop counter
2009 International SoC Design Conference (ISOCC)
·
Jan 2009
·
10.1109/SOCDC.2009.5423916